Proprio ieri vi abbiamo parlato di una ricerca destinata a sviluppare telecamere che possano riconoscere quello che riprendono ed interpretarne le possibili interazioni grazie all’intelligenza visiva.
Oggi invece vi parleremo di I2T, acronimo di “Image To Text”, ossia un sistema visivo computerizzato, sviluppato da ricercatori della UCLA californiana in collaborazione con la ObjectVideo della Virginia.
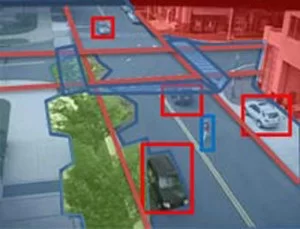
Il software alla base di I2T contiene una serie di algoritmi visivi che analizzano le immagini, e sono in grado di compilare una sorta di lista di quello che vedono all’interno di tale immagine. L’immagine, in pratica, viene scomposta in una serie di forme, alle quali viene poi associato un nome.
Il processo di associazione di forme e nomi, in realtà, contiene un fattore umano. Infatti, il progettista del sistema, Song-Chun Zhu, nel 2005 aveva partecipato ad un progetto che, con la collaborazione di alcune decine di studenti d’arte, aveva catalogato un database di oltre due milioni di immagini, identificandone il contenuto e classificandole in oltre 500 diverse categorie.
In pratica, una volta scomposta l’immagine ripresa in una serie di forme, tali forme vengono confrontate con questo archivio e viene loro assegnato un nome. Inoltre, il sistema Image To Text è in grado di rilevare i movimenti degli oggetti all’interno del filmato e di descriverli generando frasi quali “Uomo1 entra in automobile a 23:45 ed esce dall’automobile a 26:14”.
Gli oggetti possono anche essere memorizzati e riconosciuti, in modo che se un’automobile già vista rientra nel campo visivo della telecamera, venga sempre chiamata, ad esempio, Automobile1 e non Automobile2.
Il sistema I2T, che potrebbe certamente essere utilissimo per sistemi di videosorveglianza a circuito chiuso, deve ancora essere ampiamente perfezionato prima di poter essere in grado di competere con le capacità cognitive umane ed essere finalmente commercializzato. Quindi i nostri amici guardiani notturni possono dormire sonni tranquilli, il loro lavoro non è a rischio!